
Problem Detail: From this main picture explaining how skip lists work from Wikipedia, we see that some nodes carry different amounts of pointers to other parts of the list: 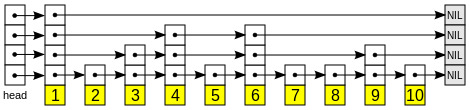 Wouldn’t it make more sense to have every node carry 4 pointers (since this is the height of this specific example)? For instance, node with value 2 would also have pointers to nodes 4, 6 and 7 and not just to node 3. I’m asking because I need a data structure that would allow me to traverse the list as quickly as possible. Having each node carry as many pointers as possible would allow me to carry out lots of parallel requests. Also, each arrow in my implementation is actually a network call, so if I can achieve higher concurrency to retrieve all 10 items would be best.
Wouldn’t it make more sense to have every node carry 4 pointers (since this is the height of this specific example)? For instance, node with value 2 would also have pointers to nodes 4, 6 and 7 and not just to node 3. I’m asking because I need a data structure that would allow me to traverse the list as quickly as possible. Having each node carry as many pointers as possible would allow me to carry out lots of parallel requests. Also, each arrow in my implementation is actually a network call, so if I can achieve higher concurrency to retrieve all 10 items would be best.
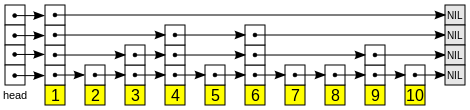 Wouldn’t it make more sense to have every node carry 4 pointers (since this is the height of this specific example)? For instance, node with value 2 would also have pointers to nodes 4, 6 and 7 and not just to node 3. I’m asking because I need a data structure that would allow me to traverse the list as quickly as possible. Having each node carry as many pointers as possible would allow me to carry out lots of parallel requests. Also, each arrow in my implementation is actually a network call, so if I can achieve higher concurrency to retrieve all 10 items would be best.
Wouldn’t it make more sense to have every node carry 4 pointers (since this is the height of this specific example)? For instance, node with value 2 would also have pointers to nodes 4, 6 and 7 and not just to node 3. I’m asking because I need a data structure that would allow me to traverse the list as quickly as possible. Having each node carry as many pointers as possible would allow me to carry out lots of parallel requests. Also, each arrow in my implementation is actually a network call, so if I can achieve higher concurrency to retrieve all 10 items would be best.
Asked By : Luca Matteis
Answered By : jbapple
In the usual way, where each node carries $i$ pointers with probability $2^{-i}$, the average node has size $O(1)$, so the total space used by the skip list is $O(n)$. If each node carried pointers at every level, then each node would have $theta(log n)$ pointers in it, since that is the expected height of a skip list with $n$ nodes. The total space used would thus be $theta(n log n)$. A skip list of one million nodes would thus be using roughly 10 times as much space.
Best Answer from StackOverflow
Question Source : http://cs.stackexchange.com/questions/51972 Ask a Question Download Related Notes/Documents
